DynamoDBからMySQLにデータを「JSON型で」転送する案件があったので、AWS Glueを使用して行ってみました。
やりたいこと
DynamoDBからMySQLにJSON型で転送するGlueジョブを実装する
前提
- Glue JobはPySpark(Python)で実装しています。
- ターゲットのMySQLはGlueからネットワークの疎通が通るのであれば、EC2, RDS, Aurora, Aurora Serverlessのどれかは問いません。
- AWS Glue Data Catalogは使用しません。
- 増分での転送(追記)ではなく、ジョブの実行ごとにテーブルを新規作成して毎回全データを移行する手法です
MySQLのJSON型について
「MySQLにJSON型で送る?そんなことできるの?」という方もいらっしゃるかもしれませんが、MySQLではバージョン5.7から「JSON型」がサポートされました。
詳細は省略しますが、その名通り「json」という型のカラムを作成すればJSON型で格納が可能になります。
記事では省略する事前準備
※全部載せると量が多くなってしまうため、ジョブのコードのみにフォーカスしました。
- VPC・サブネット・セキュリティグループ・ネットワークACLの構築
- GlueコネクションのサブネットからMySQLに疎通が通る様に構築をしてください。
- MySQL・DynamoDBの構築
- MySQLユーザの作成
- GlueコネクションなどGlueジョブ以外の設定・CloudFormationテンプレートの作成
- こちらで紹介しています
やりかた
要件
- 転送元:指定した文字列をプレフィックスに持つ複数のDynamoDBテーブル
- プレフィックス例:target-tbl
- 対象テーブル:target-tbl1, target-tbl2, target-tbl3, etc...
- プレフィックス例:target-tbl
- 転送先:指定した名前のデータベース
GlueジョブのDefaultArguments
※各Argumentsには--の指定が必要です
(--JOB_NAMEと入力する。--がないといけない仕様。)
| 引数名 | 内容 |
|---|---|
| --JOB_NAME | Glueジョブ名 |
| --connection_name | Glue Connection名 |
| --target_table_prefix | 転送元DynamoDBのテーブル名のプレフィックス |
| --default_mysql_db | 転送先MySQLのデータベース名 |
Glueジョブ(Python)
※GitHubにもあります。
import sys import boto3 import pymysql import json import re from pyspark.sql.types import * from pyspark.sql.functions import * from pyspark.context import SparkContext from awsglue.context import GlueContext from awsglue.job import Job from awsglue.utils import getResolvedOptions def get_all_tablenames(dynamodb): try: res = dynamodb.tables.all() return res except Exception as e: return e arg_keys = [ 'JOB_NAME', 'connection_name', 'target_table_prefix', 'default_mysql_db' ] args = getResolvedOptions(sys.argv, arg_keys) (job_name, connection_name, target_table_prefix, default_mysql_db) = [args[k] for k in arg_keys] sc = SparkContext() glue_context = GlueContext(sc) spark = glue_context.spark_session job = Job(glue_context) job.init(job_name, args) jdbc_conf = glue_context.extract_jdbc_conf(connection_name) mysql_host = re.findall('jdbc:mysql://(.*):3306', jdbc_conf['url']) try: mysql_conn = pymysql.connect( host=mysql_host[0], user=jdbc_conf['user'], passwd=jdbc_conf['password'], db=default_mysql_db, cursorclass=pymysql.cursors.DictCursor, connect_timeout=10 ) with mysql_conn.cursor() as cursor: sql = "SELECT TABLE_NAME FROM information_schema.TABLES WHERE TABLE_SCHEMA = %s AND TABLE_NAME LIKE %s" cursor.execute(sql, (default_mysql_db, target_table_prefix.replace('-', '_') + "\\_%")) results = cursor.fetchall() for r in results: table_name = r['TABLE_NAME'] sql = "DROP TABLE IF EXISTS " + table_name cursor.execute(sql) dynamodb = boto3.resource('dynamodb') for table in get_all_tablenames(dynamodb): if target_table_prefix in table.table_name: mysql_table_name = table.table_name.replace('-', '_') sql = "CREATE TABLE " + mysql_table_name + \ " (json_data JSON) ENGINE = Innodb" cursor.execute(sql) dyf = glue_context.create_dynamic_frame.from_options( connection_type="dynamodb", connection_options={ "dynamodb.input.tableName": table.table_name, "dynamodb.throughput.read.percent": "1.0", "dynamodb.splits": "100" } ) raw_count = dyf.count() if raw_count > 0: print( table.table_name + ' : raw count(>0) = ' + str(raw_count) ) dyf_df = dyf.toDF() dyf_df_json = dyf_df.toJSON() json_list = dyf_df_json.collect() data_list = [] for row in json_list: data_list.append({"json_data": row}) df = spark.createDataFrame(data_list) df.write \ .format("jdbc") \ .option("url", "{0}/{1}".format(jdbc_conf['url'], default_mysql_db)) \ .option("dbtable", mysql_table_name) \ .option("user", jdbc_conf['user']) \ .option("password", jdbc_conf['password']) \ .mode("append") \ .save() job.commit() except: print("ERROR: Unexpected error.") sys.exit() finally: mysql_conn.close()
解説
DynamoDBから全テーブル名を取得する関数を作っておきます。
def get_all_tablenames(dynamodb): try: res = dynamodb.tables.all() return res except Exception as e: return e
DefaultArgumentsで渡した引数を格納します。
arg_keys = [
'JOB_NAME',
'connection_name',
'target_table_prefix',
'default_mysql_db'
]
args = getResolvedOptions(sys.argv, arg_keys)
(job_name,
connection_name,
target_table_prefix,
default_mysql_db) = [args[k] for k in arg_keys]
Sparkセッション作成、ジョブの初期化をし、Glueコネクションから接続情報などを取得しておきます。
sc = SparkContext() glue_context = GlueContext(sc) spark = glue_context.spark_session job = Job(glue_context) job.init(job_name, args) jdbc_conf = glue_context.extract_jdbc_conf(connection_name) mysql_host = re.findall('jdbc:mysql://(.*):3306', jdbc_conf['url'])
取得した接続情報をもとにMySQLに接続を張ります。
mysql_conn = pymysql.connect(
host=mysql_host[0],
user=jdbc_conf['user'],
passwd=jdbc_conf['password'],
db=default_mysql_db,
cursorclass=pymysql.cursors.DictCursor,
connect_timeout=10
)
本記事前半の「前提」で記載した通り、増分での転送ではなく、毎回新規作成して全データを移行する手法のため、まず最初に転送するテーブルがあらかじめ存在していたら削除します。
MySQLのinformation_schema.TABLESというMySQLが提供しているテーブル情報用テーブルから、本ジョブで指定するDBの、指定したプレフィックスを持つテーブル一覧を取得します。
取得したテーブル名をもとにDROPクエリを構成し、実行して全テーブルをループで削除します。
with mysql_conn.cursor() as cursor: sql = "SELECT TABLE_NAME FROM information_schema.TABLES WHERE TABLE_SCHEMA = %s AND TABLE_NAME LIKE %s" cursor.execute(sql, (default_mysql_db, target_table_prefix.replace('-', '_') + "\\_%")) results = cursor.fetchall() for r in results: table_name = r['TABLE_NAME'] sql = "DROP TABLE IF EXISTS " + table_name cursor.execute(sql)
その後DynamoDBと接続して先程の関数を使用して全テーブル名を取得し、1テーブルごとにループをして「DynamoDBから取得->MySQLに転送」を繰り返していきます。
最初に指定したプレフィックス(target_table_prefix)を持つテーブルであれば、そのテーブル名をもとにCREATE TABLE文を生成し、実行します。
json_data JSONというように、JSON型のカラムを1つのみ定義しています。
その際に、DynamoDBのテーブル名で「-(ハイフン)」を使用していたら、「_(アンダーバー)」に変換します。(好みや規約で変えてください。)
また、MySQLのエンジンはInnodbを指定します。(最近のMySQLを使用していれば指定しなくても問題ないのですが念のため)
dynamodb = boto3.resource('dynamodb') for table in get_all_tablenames(dynamodb): if target_table_prefix in table.table_name: mysql_table_name = table.table_name.replace('-', '_') sql = "CREATE TABLE " + mysql_table_name + \ " (json_data JSON) ENGINE = Innodb" cursor.execute(sql)
ここでようやくDynamoDBからデータを取得します。
具体的には、最初に生成したglue_contextからcreate_dynamic_frame.from_optionsでDynamicFrameを生成します。
DynamicFrameとは、SparkのDataFrameのようなものであり、Glue独自の型・データ構造です。後ほどDataFrameと変換したりします。
dyf = glue_context.create_dynamic_frame.from_options(
connection_type="dynamodb",
connection_options={
"dynamodb.input.tableName": table.table_name,
"dynamodb.throughput.read.percent": "1.0",
"dynamodb.splits": "100"
}
)
DynamicFrameのcount()によって、そのテーブルの行数を取得できます。0行じゃない場合のみ挿入処理へと進みます。
またprintは、挿入処理へ進むテーブルをわかりやすくログに残すためのものなのでお好みでどうぞ。
raw_count = dyf.count()
if raw_count > 0:
print(
table.table_name +
' : raw count(>0) = ' +
str(raw_count)
)
次がこのジョブの1番の肝です。
dyf_df = dyf.toDF()
dyf_df_json = dyf_df.toJSON()
まず、toDF()というメソッドによって、DynamicFrameからDataFrame(≒DynamicFrameのSpark版)に変換します。
※DataFrameの詳細の説明は公式をご覧下さい。 spark.apache.org
なぜこうしたかというと、DataFrameのtoJSON()というメソッドを使いたかったからです。
これは、各レコードを1つのJSONに変換するというもので、まさに今回の要件にピッタリなメソッドです。
DynamicFrameでこのようなメソッドが見つからなかった(もしあれば教えてください)のでこちらを選択し、そのためにDataFrameに変換し、toJSON()によりJSONデータを生成しています。
そして、collect()によって実際にテーブルのデータを取得し、ループで1行ずつ回します。
ここで、このJSONデータ自体をバリューとして、そのキーをMySQLのテーブルのカラム名に合わせてjson_dataにしないとテーブルとのマッピングが出来ず挿入できないので、わざわざループで1レコードずつ整形をして配列に再格納しています。
配列に全データを格納するということはかなりメモリを使うので、今後の修正TODOにしたいと思います。(※DynamicFrameから直接、レコードの値全体を1つのバリューとして新たにキーをつけるメソッドがあればいいのですが。。。)
json_list = dyf_df_json.collect()
data_list = []
for row in json_list:
data_list.append({"json_data": row})
そして再作成した配列をもとにDataFrameを生成(createDataFrame)し、writeメソッドでターゲットのMySQLのテーブルに全行挿入します。
※DynamicFrameからでも書き込めますが、DataFrameでは書き込み方法の区別(.mode())ができるため、実行の比較のためにDataFrameから書き込みをしています。
df = spark.createDataFrame(data_list)
df.write \
.format("jdbc") \
.option("url", "{0}/{1}".format(jdbc_conf['url'], default_mysql_db)) \
.option("dbtable", mysql_table_name) \
.option("user", jdbc_conf['user']) \
.option("password", jdbc_conf['password']) \
.mode("append") \
.save()
.mode()にはappendとoverwriteがあります。
| mode | 意味 | DB上の挙動 |
|---|---|---|
| append | 追記 | INSERT |
| overwrite | 上書き | DROP TABLE + CREATE TABLE + INSERT |
さらに大事なのが、overwriteだとDataFrameのレコードからカラム構成とMySQLでの型を自動で判別してCREATE TABLEを行うのですが、JSONのレコードを「JSON型」ではなく「TEXT型」として判別してしまう仕様があります。
なので本ジョブでoverwriteにしてしまうと、json_dataをTEXT型として、Glueが内部で以下の様なSQLクエリを発行します。
SELECT 1 FROM table_name LIMIT 1; DROP TABLE table_name; CREATE TABLE table_name (`json_data` TEXT );
JSON型自体が新しい型なので仕方ないですが、TEXT型ではなくJSON型で格納するという要件があるので本ジョブではoverwriteを使わず、appendにして自前でDROP TABLE + CREATE TABLEするという方法を取りました。
そして、長くなりましたがcommit()をして完了です。
最後にfinallyにてmysql_conn.close()で接続を解放もします。
job.commit() except: print("ERROR: Unexpected error.") sys.exit() finally: mysql_conn.close()
実行の仕方
こちらのジョブを手動で実行したり、Glue Trigger(定期実行用)で定期実行したりします。
データの確認
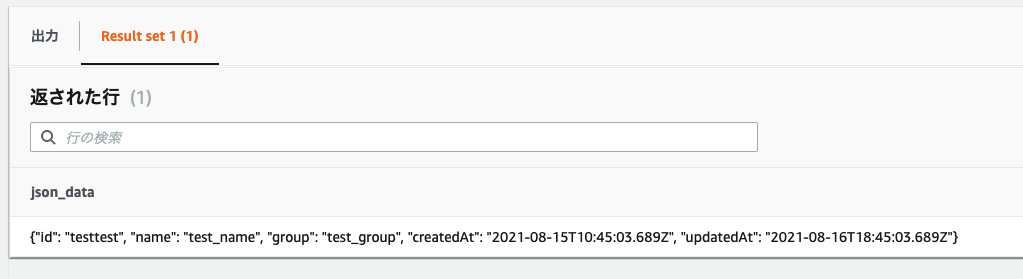
MySQL上でデータを確認すると、ちゃんとJSONの形で格納されています。
まとめ
DynamoDBからMySQLにJSON型で転送するGlueジョブを作成してみました。
ジョブ以外のことは全て省略したのにこんなに長くなってしまいました。。。
そもそもMySQLにJSONで入れることもそんなにないかと思うのですが、「正規化が面倒だけどいつもMySQLで分析しているから一緒に管理したい」「MySQLからSQLで分析したい」「MySQL側でパースしたい」などの要望にはマッチするのではないでしょうか。
ソースコード自体あまり効率の良いものにはできなかったので(JSONデータ整形部分)、今後解消していきたいと思います。